AI-自然语言处理
自然语言处理 (NLP) 是指使用自然语言(如英语)与智能系统进行通信的 AI 方法。
当您希望像机器人这样的智能系统按照您的指示执行时,当您希望听到基于对话的临床专家系统的决定时,需要处理自然语言。
NLP领域涉及使计算机使用人类使用的自然语言执行有用的任务。NLP 系统的输入和输出可以是 -
- 演讲
- 书面文本
自然语言处理的组成部分
NLP有两个组成部分 -
自然语言理解 (NLU)
理解涉及以下任务 -
- 将自然语言中的给定输入映射到有用的表示形式。
- 分析语言的不同方面。
自然语言生成 (NLG)
它是从某种内部表示中以自然语言的形式产生有意义的短语和句子的过程。
它涉及——
-
文本规划 - 它包括从知识库中检索相关内容。
-
句子规划 - 它包括选择所需的单词,形成有意义的短语,设置句子的基调。
-
文本实现 - 它将句子计划映射到句子结构中。
NLU比NLG更难。
NLU的困难
NL具有极其丰富的形式和结构。
这是非常模棱两可的。可以有不同程度的歧义 -
-
词汇歧义 − 它处于非常原始的级别,例如单词级别。
-
例如,将“板”一词视为名词或动词?
-
语法级别歧义 - 一个句子可以用不同的方式解析。
-
例如,“他举起了戴红帽的甲虫”——他是用帽子举起甲虫还是举起了一只戴着红帽的甲虫?
-
指代歧义 − 使用代词指代某物。例如,里马去了高里。她说:“我累了。
-
一个输入可能意味着不同的含义。
-
许多输入可能意味着同样的事情。
自然语言处理术语
-
音韵学 - 它是系统地组织声音的研究。
-
形态学 - 它是从原始有意义单位构建单词的研究。
-
语素 - 它是语言中含义的原始单位。
-
语法 - 它指的是排列单词来造句。它还涉及确定单词在句子和短语中的结构作用。
-
语义 - 它涉及单词的含义以及如何将单词组合成有意义的短语和句子。
-
语用学 - 它涉及在不同情况下使用和理解句子以及句子的解释如何受到影响。
-
话语 - 它涉及紧接前一句如何影响下一句的解释。
-
世界知识 - 它包括关于世界的一般知识。
自然语言处理的步骤
一般有五个步骤——
-
词汇分析 - 它涉及识别和分析单词的结构。语言词典是指一种语言中单词和短语的集合。词汇分析是将txt的整个块划分为段落,句子和单词。
-
句法分析(解析) - 它涉及分析句子中的单词的语法,并以显示单词之间关系的方式排列单词。诸如“学校去男孩”之类的句子被英语句法分析器拒绝。
-
语义分析 - 它从文本中得出确切的含义或字典含义。检查文本是否有意义。它是通过在任务域中映射句法结构和对象来完成的。语义分析器忽略诸如“热冰淇淋”之类的句子。
-
话语整合 - 任何句子的含义取决于它前面的句子的含义。此外,它还带来了紧随其后的句子的含义。
-
语用分析 - 在此期间,所说的内容被重新解释其实际含义。它涉及推导出语言中需要现实世界知识的那些方面。
句法分析的实现方面
研究人员已经为句法分析开发了许多算法,但我们只考虑以下简单方法 -
- 上下文无关语法
- 自上而下的解析器
让我们详细看看它们——
上下文无关语法
它是由重写规则左侧带有单个符号的规则组成的语法。让我们创建语法来解析句子 -
“鸟儿啄谷物”
文章 (DET) − a |一个 |这
名词 − 鸟 |鸟类 |谷物 |谷物
名词短语 (NP) − 冠词 + 名词 |文章+形容词+名词
= IT N |IT 调整后 N
动词 − 啄 |啄食 |啄
动词短语 (VP) − NP V |V NP
形容词 (调整) − 美丽 |小 |鸣叫
解析树将句子分解为结构化部分,以便计算机可以轻松理解和处理它。为了使解析算法构造此解析树,需要构建一组重写规则,描述哪些树结构是合法的。
这些规则说,某个符号可以通过一系列其他符号在树中扩展。根据一阶逻辑规则,如果有两个字符串名词短语(NP)和动词短语(VP),则由NP后跟VP组合的字符串就是一个句子。句子的重写规则如下 -
S → NP 副总裁
NP → IT N |IT 调整后 N
副总裁 → V NP
词典 −
DET → a |这
ADJ →美丽 |栖息
N →鸟 |鸟类 |谷物 |谷物
V →啄 |啄 |啄
解析树可以创建,如下所示 -
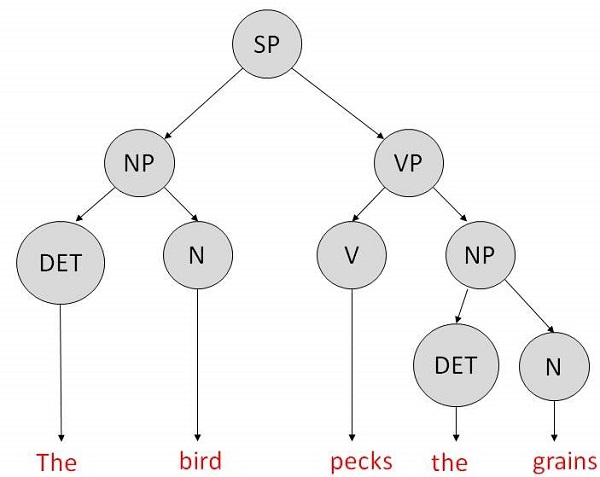
现在考虑上面的重写规则。由于 V 可以替换为“啄”或“啄”, 诸如“鸟啄谷物”之类的句子可能是错误的。即主谓 协议错误被批准为正确。
优点 - 最简单的语法风格,因此被广泛使用。
缺点 -
-
它们不是很精确。例如,“谷物啄鸟”,根据解析器在语法上是正确的,但即使它没有意义,解析器也会将其视为正确的句子。
-
为了提高高精度,需要准备多组语法。它可能需要一套完全不同的规则来解析单数和复数变体、被动句子等,这可能导致创建大量无法管理的规则。
自上而下的解析器
在这里,解析器从 S 符号开始,并尝试将其重写为与输入句子中单词的类匹配的终端符号序列,直到它完全由终端符号组成。
然后用输入的句子检查这些,看看它是否匹配。如果没有,则使用一组不同的规则重新开始该过程。重复此操作,直到找到描述句子结构的特定规则。
优点 - 它易于实施。
缺点 -
- 这是低效的,因为如果发生错误,必须重复搜索过程。
- 工作速度慢。